Il Natural Language Processing (NLP, in italiano “elaborazione del linguaggio naturale”) si occupa delle interazioni tra macchine e linguaggi umani, è un campo che appartiene all’informatica, alla linguistica e all’Intelligenza Artificiale ed è noto anche con il nome di linguistica computazionale.
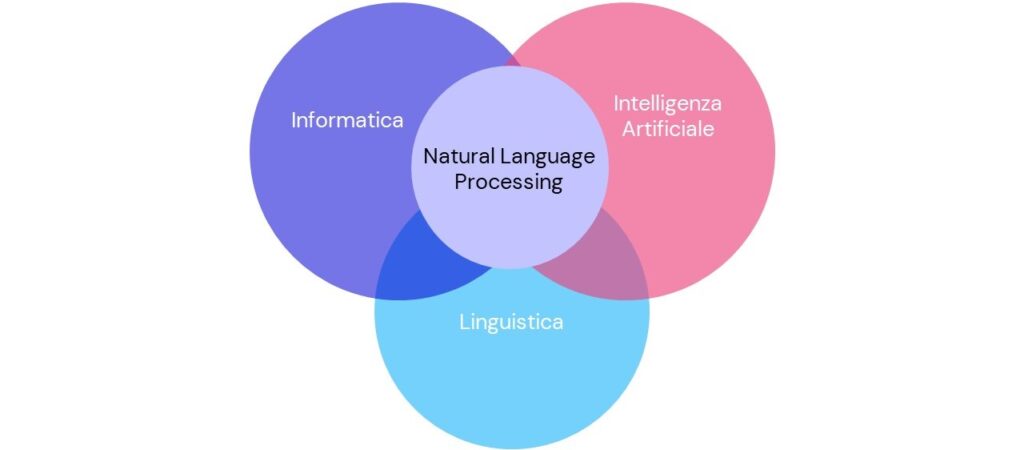
Con “linguaggio naturale” ci si riferisce al modo in cui noi umani comunichiamo.
Il Natural Language Processing (NLP) è lo strumento che ci permette di dialogare con i sistemi informatici senza modificare il nostro linguaggio fatto di sintassi, semantica, significati lessicali e strutture testuali spesso complesse. Il NLP permette di tradurre queste caratteristiche proprie del linguaggio umano in una forma di dati che le macchine siano in grado di elaborare, dato che i computer – anche i più avanzati – non sono in grado di parlare, scrivere o ragionare come facciamo noi.
Il Natural Language Processing offre dunque alle persone un modo per interfacciarsi con i sistemi informatici consentendo loro di parlare o scrivere in modo naturale, senza imparare linguaggi di programmazione.
Tuttavia, il NLP non permette solo la comunicazione uomo-macchina (immissione di input), ma anche macchina-uomo (generazione di output).
L’elaborazione del linguaggio naturale è, infatti, composta da due campi distinti:
- comprensione del linguaggio naturale (Natural Language Understanding – NLU);
- generazione del linguaggio naturale (Natural Language Generation – NLG).
Il Natural Language Processing è ciò che rende possibile molte delle funzionalità alla base dei servizi che utilizziamo tutti i giorni: traduzione automatica di testi, ricerca di informazioni all’interno di enormi database, il riconoscimento vocale.
Come funziona il Natural Language Processing
Oggi, il Natural Language Processing, combina una modellazione che si basa sulle regole del linguaggio umano, con modelli di statistica, di Machine Learning e di Deep Learning rendendo possibile ai computer l’elaborazione e la trasformazione del linguaggio umano in dati da cui è possibile estrarre significato, intenzioni e sentiment.
Dobbiamo ricordare però che esiste una differenza importante tra NLP e le attività di Machine Learning ed è legata al tipo di dati: nel primo caso vengono processati dati testuali non strutturati mentre nel secondo è necessario un dataset strutturato.
Affinché i testi non strutturati possano diventare un input per gli algoritmi di Machine Learning è necessario che intervengano i modelli di NLP, che vengano eseguite una serie di azioni, una successione di fasi che servono a minimizzare gli errori e superare eventuali ambiguità.
È infatti necessario comprendere la struttura del linguaggio umano e come trattare il testo prima di poter applicare tecniche di Machine Learning e Deep Learning.
L’elaborazione del linguaggio naturale comporta dunque una successione di fasi che tentano di superare le ambiguità del linguaggio, analizzando ogni aspetto e “livello” di questo.
Le fasi comprendono infatti:
- tokenization (scomposizione del testo in token come parole, punteggiatura, spazi, ecc.);
- analisi morfologica e lessicale;
- analisi sintattica;
- analisi semantica;
- analisi del discorso.
Cosa permette di fare il Natural Language Processing?
Le possibilità offerte dall’elaborazione del linguaggio naturale sono tante e saranno sempre maggiori, ad oggi possiamo parlare di:
- text analysis, analisi del testo ed eventuale identificazione di elementi chiave (argomenti, parole, date, ecc.);
- text classification, interpretazione di un testo per poi classificarlo, ad esempio come viene fatto per il riconoscimento dello spam;
- sentiment analysis, analisi dell’umore di una determinata frase, ad esempio per comprendere se una recensione sia positiva o negativa;
- intent monitoring, comprensione dell’intento alla base di un testo, ad esempio per prevedere futuri comportamenti di acquisto o offrire i migliori risultati a una ricerca da parte dell’utente;
- smart search, ricerca all’interno di grandi database dei documenti che meglio rispondono alla domanda posta in linguaggio naturale;
- text generation, generazioni automatiche di testo;
- automatic summarization, produzione di riassunti partendo da uno o più documenti di testo;
- language translation, traduzione di testo ottimizzata grazie alla comprensione del contesto oltre che della singola parola o frase.
La capacità di svolgere questi compiti si traduce in opportunità di notevole valore per le aziende che possono analizzare grandi quantità di testo permettendo consultazioni rapide e efficaci, individuare i messaggi indesiderati ed addestrare di conseguenza i programmi di email, analizzare il sentiment sui canali social per monitorarne l’andamento e avere il polso della propria reputazione, indirizzare velocemente e puntualmente le ricerche degli utenti verso i risultati più pertinenti, e molto altro ancora.
Che rapporto c’è tra Natural Language Processing, Machine Learning e Deep Learning?
Natural Language Processing, Machine Learning e Deep Learning sono ambiti appartenenti al mondo dell’Intelligenza Artificiale strettamente connessi tra loro. Abbiamo anche visto che il NLP può elaborare testi non strutturati mentre il Machine Learning analizza testi strutturati. A questo possiamo aggiungere che il Machine Learning permette di applicare le tecniche di Intelligenza Artificiale al NLP in modo che questo acquisisca capacità di apprendimento. Questi concetti e le loro evoluzioni si sono intersecati fin dalla loro nascita, ma recentemente ci sono state evoluzioni importanti.
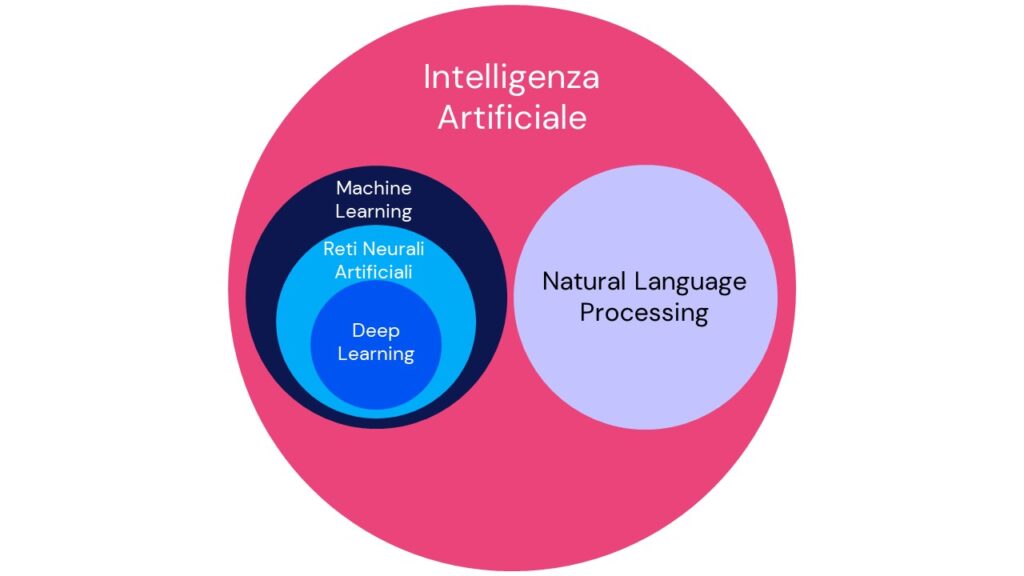
Il notevole sviluppo, che attualmente caratterizza il Deep Learning, ha permesso di inserire l’uso delle Reti Neurali Artificiali all’interno dell’interpretazione del linguaggio naturale.
OpenAI nel 2020 ha rilasciato il suo modello linguistico basato proprio sulle reti neurali, integrandolo interamente in ChatGPT.
E tra Natural Language Processing e Large Language Model?
Partiamo dal capire che cos’è un Large Language Model o LLM. Un Large Language Model è un modello matematico di distribuzione della probabilità delle parole che massimizza la sua capacità di predire il testo corretto minimizzando gli errori.
I Large Language Model sono una branca del Natural Language Processing. Consistono in algoritmi addestrati su un’elevata mole di dati per interpretare, comprendere e trattare il linguaggio naturale con l’obiettivo di produrre autonomamente testi.
Tra i pionieri nello studio ed utilizzo dei LLM troviamo sicuramente Google che nel 2017 inventò il modello di linguaggio Transformer (che si trova alla base di BERT, la base di partenza del motore di ricerca che ben conosciamo, e di GPT, il modello utilizzato da OpenAI) che ha permesso di includere la dimensione del contesto nell’analisi probabilistica del linguaggio.
In sintesi, possiamo dire che gli LLM siano la forma più avanzata di Natural Language Processing e che gli incredibili sviluppi degli ultimi anni hanno portato a enormi successi nel campo dell’elaborazione naturale del testo, permettendo costanti ed incredibili miglioramenti in molte attività come la traduzione automatica, l’analisi del sentiment, e soprattutto la generazione del testo.
Continua ad approfondire, leggi altri atri articoli Skilla!
