Nel 2021, un gruppo di studiosi dell’Università di Stanford introdusse il termine “foundation models” nel report On the Opportunities and Risks of Foundation Models. Per comprendere la natura, le funzioni e le potenziali applicazioni di questi modelli, ci baseremo principalmente su questo documento.
Definizione
Nell’ambito dell’Intelligenza Artificiale (IA), con il termine “modello” si fa riferimento a un insieme strutturato di algoritmi e parametri che permettono di eseguire specifici compiti di apprendimento automatico. I modelli sono addestrati tramite l’analisi e l’elaborazione di dati, al fine di identificare e apprendere schemi o relazioni tra di essi.
Un foundation model rappresenta un tipo specifico e avanzato di modello di Intelligenza Artificiale.
I modelli “generici” di Intelligenza Artificiale sono progettati e addestrati per svolgere compiti specifici e ben definiti e possono essere addestrati su set di dati di dimensioni variabili, a seconda del compito che dovranno svolgere.
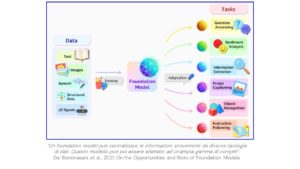
I foundation models, invece, sono addestrati su enormi quantità di dati e con moltissimi parametri. Ciò permette loro di svolgere una varietà di compiti più ampia rispetto ai modelli tradizionali.
I foundation models possono dunque essere definiti come “modelli di base di grandi dimensioni”. “Di base” perché, grazie alla loro capacità di svolgere diversi compiti, fungono da “fondamenta” o punto di partenza per lo sviluppo di sistemi avanzati.
Caratteristiche dei foundation models
È interessante notare che gli autori del report specificano subito che i foundation models non sono, dal punto di vista tecnologico, una novità. Essi si fondano su Reti Neurali profonde e apprendimento non supervisionato, entrambe tecnologie esistenti da più di un decennio.
Tuttavia, è la portata e l’ampiezza dei modelli sviluppati negli ultimi anni a segnare una notevole differenza rispetto al passato.
Esempi attuali di foundation models sono GPT-3 e 4 di OpenAI e BERT di Google. Per avere un’idea della dimensione e della rapida evoluzione di questi modelli, basti pensare che GPT-3, rilasciato nel giugno 2020, utilizza 175 miliardi di parametri, mentre GPT-4, rilasciato nel marzo 2023, ben 100 trilioni.
Le principali caratteristiche dei foundation models si possono riassumere in emersione e omogeneizzazione.
- Emersione
Nel report si legge che emersione “significa che il comportamento di un sistema è implicitamente indotto piuttosto che esplicitamente costruito”. Ciò indica che molte capacità di questi modelli emergono durante il processo di addestramento senza che vengano espressamente programmate.
In altre parole, i foundation models sono capaci di apprendere compiti complessi e specifici non perché siano stati progettati in modo esplicito per svolgerli, ma perché hanno analizzato e processato enormi quantità di dati, acquisendo in modo autonomo determinate capacità. - Omogeneizzazione
I foundation models sono progettati per essere altamente generalisti in modo da poter essere utilizzati in molti contesti e per molteplici applicazioni. Questo significa che essi omogeneizzano, o rendono uniformi, le capacità di varie applicazioni di Intelligenza Artificiale. Invece di avere diversi modelli piccoli e specializzati, c’è un unico, grande modello che può essere adattato a vari compiti.
Possibili rischi
Emersione ed omogeneizzazione sono caratteristiche incredibili che evidenziano il progresso in questo settore e le sue potenzialità future, ma portano anche dei rischi.
L’omogeneizzazione può essere vantaggiosa in settori con scarsità di dati disponibili (come sanità e istruzione, a causa delle normative sulla privacy), in quanto permette l’uso di modelli generalisti in diversi contesti. Tuttavia, questo comporta anche che difetti, imprecisioni ed errori del modello originario possano essere trasferiti a tutti i modelli derivati, sollevando problemi etici e di equità.
Riguardo all’emersione, se da un lato rappresenta la “forza” e il principale vantaggio di questi modelli, dall’altro lato ne complica l’interpretazione, la valutazione e la previsione. Tale mancanza di trasparenza e comprensibilità può generare criticità in termini di sicurezza e robustezza.
Prospettiva a ecosistema
Ciò che rende interessanti ed importanti i foundation models non sono solo le loro caratteristiche e notevoli prestazioni, ma anche il fatto che sono rapidamente integrati in prodotti e strumenti utilizzati da moltissime persone. Nei paragrafi precedenti abbiamo citato i modelli GPT 3 e 4 e BERT. Quest’ultimo è alla base di Google Search, servizio che vanta circa 4 miliardi di utenti.
È lecito dunque porsi domande quali: Qual è l’impatto sociale di questi modelli? Data la loro natura complessa e in evoluzione, come possiamo anticipare e affrontare responsabilmente le conseguenze etiche e sociali che sollevano?
Per rispondere a queste domande, i ricercatori di Stanford suggeriscono di adottare una prospettiva ad ecosistema. Ciò significa analizzare tutte le fasi e i soggetti coinvolti nel loro sviluppo: dall’analisi dei processi attraverso i quali i dati sono selezionati, organizzati e preparati per l’addestramento, all’esame degli specifici compiti che vengono svoli o applicazioni che ne derivano. È importante considerare anche le implicazioni degli adattamenti sul funzionamento dei modelli stessi.
Questa prospettiva aiuta a comprendere che le responsabilità e la governance dei foundation models sono distribuite tra diversi attori e fasi dell’ecosistema dei modelli, e che è necessario un approccio coordinato e multidisciplinare per gestirli in modo etico e responsabile.
Applicazioni
I foundation models, come abbiamo visto, sono in grado di svolgere svariati compiti. Gran parte di questi rientrano nell’ambito del Natural Language Processing: come, ad esempio, produrre testi, rispondere alle domande, tradurre, sentiment analysis etc.
Tramite invece i vision foundation models, che sfruttano algoritmi di computer vision, è possibile classificare immagini, individuare un oggetto o perfino riconoscere un deep fake.
Tra le numerose applicazioni dei foundation models, gli autori del report On the Opportunities and Risks of Foundation Models scelgono di focalizzarsi su tre settori cruciali: sanità, diritto ed educazione. L’obiettivo è illustrare l’impatto significativo e le modalità di utilizzo di questi modelli in ambiti essenziali della vita quotidiana.
- Nella sanità, i foundation models promettono di superare le limitazioni legate alla scarsità e al costo elevato dei dati, permettendo l’analisi di diverse tipologie di informazioni, dai testi alle strutture molecolari. Tuttavia, esiste il pericolo di perpetuare possibili pregiudizi storici presenti nei dati medici.
- Nel diritto, l’abbondanza di documenti legali rende ideale l’utilizzo di questi modelli, che potrebbero rivoluzionare la creazione e l’analisi dei testi giuridici. L’importanza della veridicità delle informazioni generate non può però essere sottovalutata. I foundation models dovrebbero garantire coerenza e accuratezza.
- Nel settore educativo, i foundation models possono sfruttare diverse fonti, come libri di testo e video, per supportare l’apprendimento. Offrono potenziali benefici come la generazione di esercizi e feedback personalizzati, ma presentano anche rischi quali problemi di privacy, possibilità di plagio e le disuguaglianze nell’accesso alle tecnologie.
Conclusioni
Come spesso accade nello sviluppo delle tecnologie di Intelligenza Artificiale, anche nel caso dei foundation models, ci troviamo a oscillare tra l’entusiasmo per i numerosi vantaggi e il vasto potenziale offerto, e la necessità di riflettere attentamente su questioni etiche e sociali cruciali.
Nei prossimi anni, è molto probabile che assisteremo ad una crescente diffusione di questi modelli. Pertanto, è essenziale mantenere uno sguardo critico e attento, impegnandoci a comprenderli meglio, magari adottando proprio la prospettiva a ecosistema suggerita dagli studiosi di Stanford.
